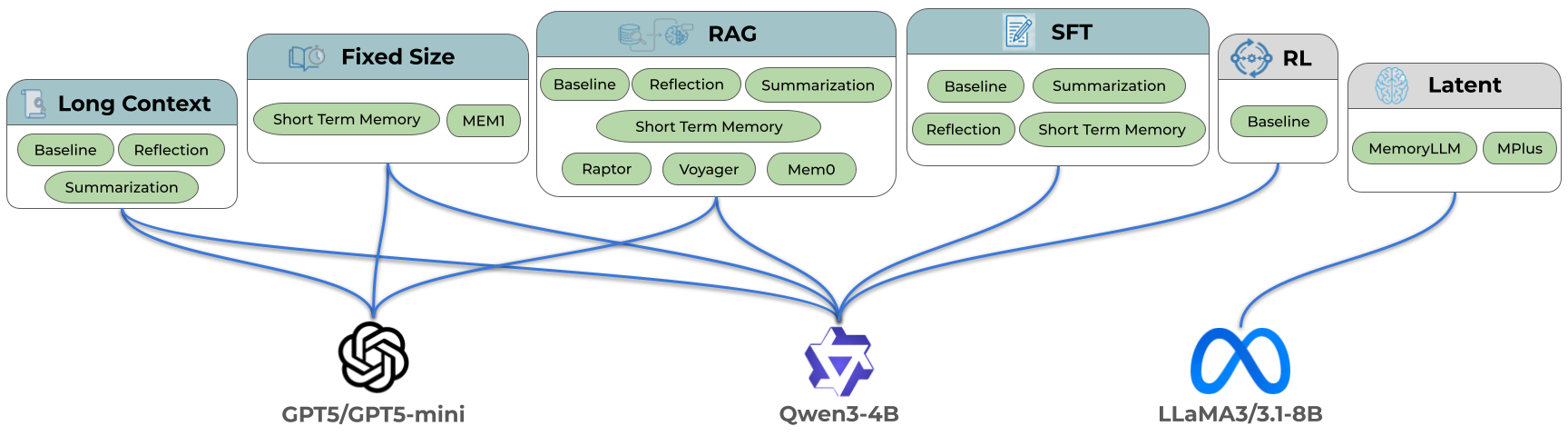
Agent Paradigms
AgentOdyssey implements and evaluates 11 methods spanning a range of LLM-based agents grouped into six paradigms, plus two additional baselines (no-memory and random actions). All LLM-based agents adopt the ReAct prompting method, producing a reasoning trace before selecting an action at each step.
We evaluate both proprietary (GPT-5, GPT-5-mini, Claude-Opus-4.6, Grok-4.1-Fast) and open-weight LLM (Qwen3-4B) backbones. Latent agents (MemoryLLM and MPlus) additionally use LLaMA-3.1-8B, as these models are trained on and only compatible with the LLaMA-3 family. The diagram below details the agent families that we've implemented and evaluated in AgentOdyssey.
Baselines
No-Memory Agent (NoMemoryAgent) uses an LLM to decide actions based solely on the current observation.
Random Agent (RandomAgent) selects a uniformly random action from the set of valid actions at each step. No LLM is involved. This provides a lower bound on performance.
Long Context Agents
Long Context Agents (LongContextAgent) append every observation, reasoning trace, and action to an unbounded text buffer. At each step the entire history is passed in the prompt. The prompt may grow without limit, eventually hitting the model's context window ceiling or degrading in quality as the history lengthens.
Fixed-Size Memory Agents
Fixed-Size Memory Agents maintain a bounded context to manage memory, avoiding the unbounded growth of long context approaches. AgentOdyssey implements two variants under this paradigm:
Short-Term Memory Agent (ShortTermMemoryAgent) keeps a sliding window of the most recent N observation–reasoning–action tuples (default N = 5). Older entries are discarded.
Mem1 Agent (Mem1Agent) maintains a single cumulative information state (an <IS>...</IS> block) that is trimmed to a fixed token budget (max_memory_tokens, default 512). At each step the LLM is asked to update this summary given the new observation. This approach is based on Mem1.
RAG Agents
RAG (Retrieval-Augmented Generation) Agents store each observation–reasoning–action tuple in an external database of embedding–text pairs. At inference time, the agent retrieves the top-k most relevant entries and appends them to the model context for decision-making. AgentOdyssey implements four variants:
Vanilla RAG Agent (VanillaRAGAgent) embeds each step's text using a HuggingFace embedding model and retrieves the top-k entries by cosine similarity. This is the standard dense-retrieval baseline.
Mem0 RAG Agent (Mem0RAGAgent) uses the Mem0 library, which internally manages memory extraction via an LLM and indexes entries with FAISS. Mem0 decides what to remember and how to consolidate memories.
Raptor RAG Agent (RaptorRAGAgent) implements RAPTOR-style hierarchical retrieval. Rather than storing flat chunks, it builds a tree of progressively summarized text and retrieves from multiple levels of abstraction.
Voyager Agent (VoyagerAgent) adapts the Voyager architecture: a curriculum agent proposes tasks, an action agent executes them, a critic judges success, and successful traces are distilled into reusable skills stored in an embedding-indexed skill library. This tests whether a multi-module planning approach helps in a memory-demanding environment.
SFT Agents
SFT (Supervised Fine-Tuning) Agents encode experience directly into model parameters. After accumulating a buffer of recent steps, the agent fine-tunes its own weights on those texts via causal language model loss, then resets the buffer.
LoRA SFT Agent (LoRASFTAgent) wraps the base LLM with a LoRA adapter (rank 16, alpha 32, targeting attention projections) and trains only the adapter weights.
Full SFT Agent (FullSFTAgent) fine-tunes all model parameters.
Latent Agents
Latent Agents compress experience into learnable latent memory tokens that are integrated into the model's hidden states, enabling persistent storage and retrieval without explicit text retrieval or parameter updates.
MemoryLLM Agent (MemoryLLMAgent) uses MemoryLLM, which injects text into an internal memory pool via inject_memory(). The memory is stored as latent vectors inside the model's hidden dimension and is updated as new information is injected. Based on LLaMA-3.1-8B.
MPlus Agent (MPlusAgent) uses M+, a successor to MemoryLLM with an improved memory architecture. It also injects memory via inject_memory() and stores it as latent vectors. Based on LLaMA-3.1-8B.
Optional Augmentations
The paradigms above can be optionally augmented with the following strategies, enabled via configuration flags:
- Reflection (
enable_reflection): before acting, the agent performs an LLM-based self-reflection on its retrieved or stored memory in light of the current observation, then appends the reflection to memory. - Summarization (
enable_summarization): instead of storing raw observation–reasoning–action text, the agent first summarizes it via the LLM, reducing the text stored in memory. - Short-term memory (
enable_short_term_memory): a fixed-size sliding window (default 5 entries) of the most recent tuples, layered on top of the main memory mechanism. For RAG agents this provides immediate recent context alongside retrieved long-term memories.