So... What is AgentOdyssey?
Abstract
For agents to learn continuously from interaction with the world at test time, they must be able to explore effectively, acquire new world knowledge and skills, retain relevant episodic experiences, and plan over long horizons. To evaluate these key abilities of test-time continual learning agents, we introduce AgentOdyssey, a novel evaluation framework that procedurally generates open-ended text games with rich entities, world dynamics, and long-horizon tasks. Critically, AgentOdyssey goes beyond the conventional machine learning assumption that learning does not occur at test time by placing agents in a continuous, long-horizon setting that interleaves learning and inference throughout deployment. We further propose a multifaceted evaluation methodology that measures not only game progress but also offers diagnostic tests on world knowledge acquisition, episodic memory, object and action exploration, action diversity, and model cost. We evaluate a diverse set of agent paradigms in the generated games, and our experiments reveal critical limits in agents' key abilities, as well as factors that influence their meaningful horizon. Although performance scales with stronger base models, even the top agent remains far below human performance, leaving substantial headroom for improvement. Among agent mechanisms, we find that short-term memory benefits multiple agent paradigms and is an important component of agentic test-time training.
Five Key Abilities
AgentOdyssey evaluates the key abilities required for test-time continual learning agents.
Exploration
Actively discovering new areas, objects, and actions to find resources and unlock future possibilities.
Episodic Memory
Remembering past experiences, such as where items were dropped, which areas were visited, and what happened when.
World Knowledge Acquisition
Learning novel facts about the environment through interaction, such as crafting recipes and NPC behaviors.
Skill Learning
Acquiring procedural skills like combat strategies and note-taking to improve task efficiency over time.
Long-Horizon Planning
Decomposing complex objectives into subgoals and managing multiple goals across hundreds of steps.
Framework Overview
Procedural Game Generation
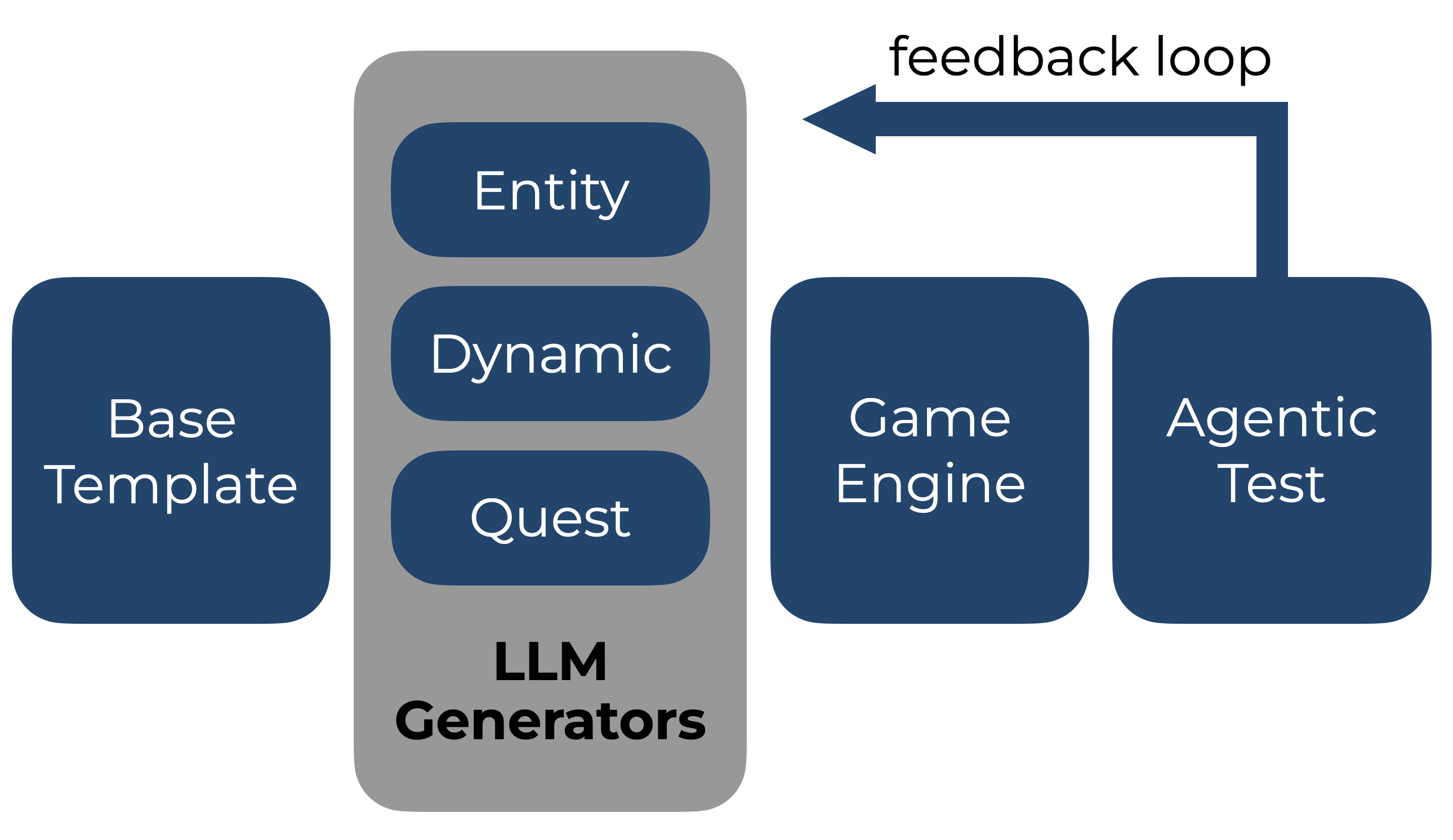
Diverse Agent Paradigms
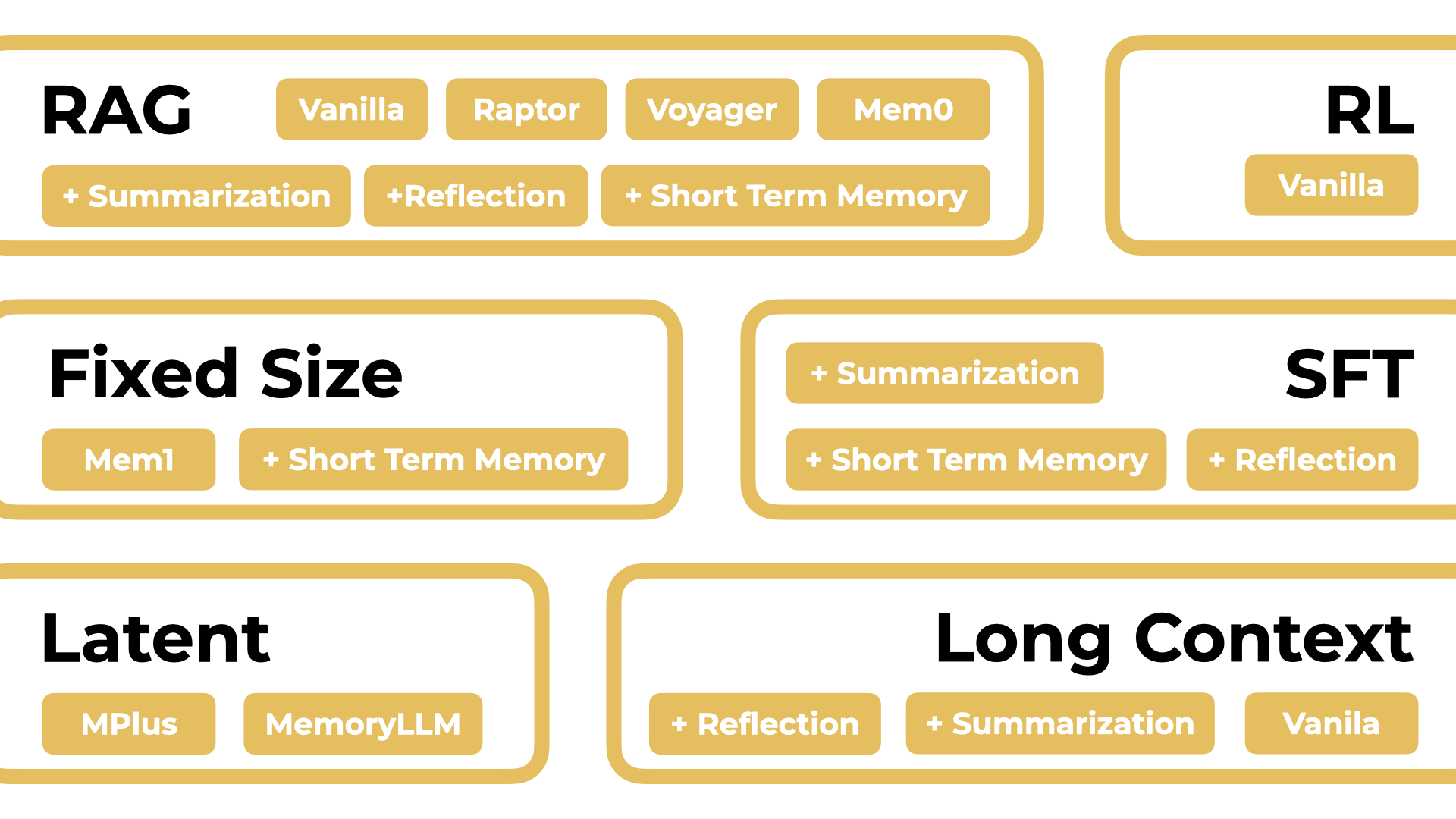
Multifaceted Evaluation
Results and Key Findings
From experiments across diverse agent paradigms and LLM backbones on procedurally generated games.
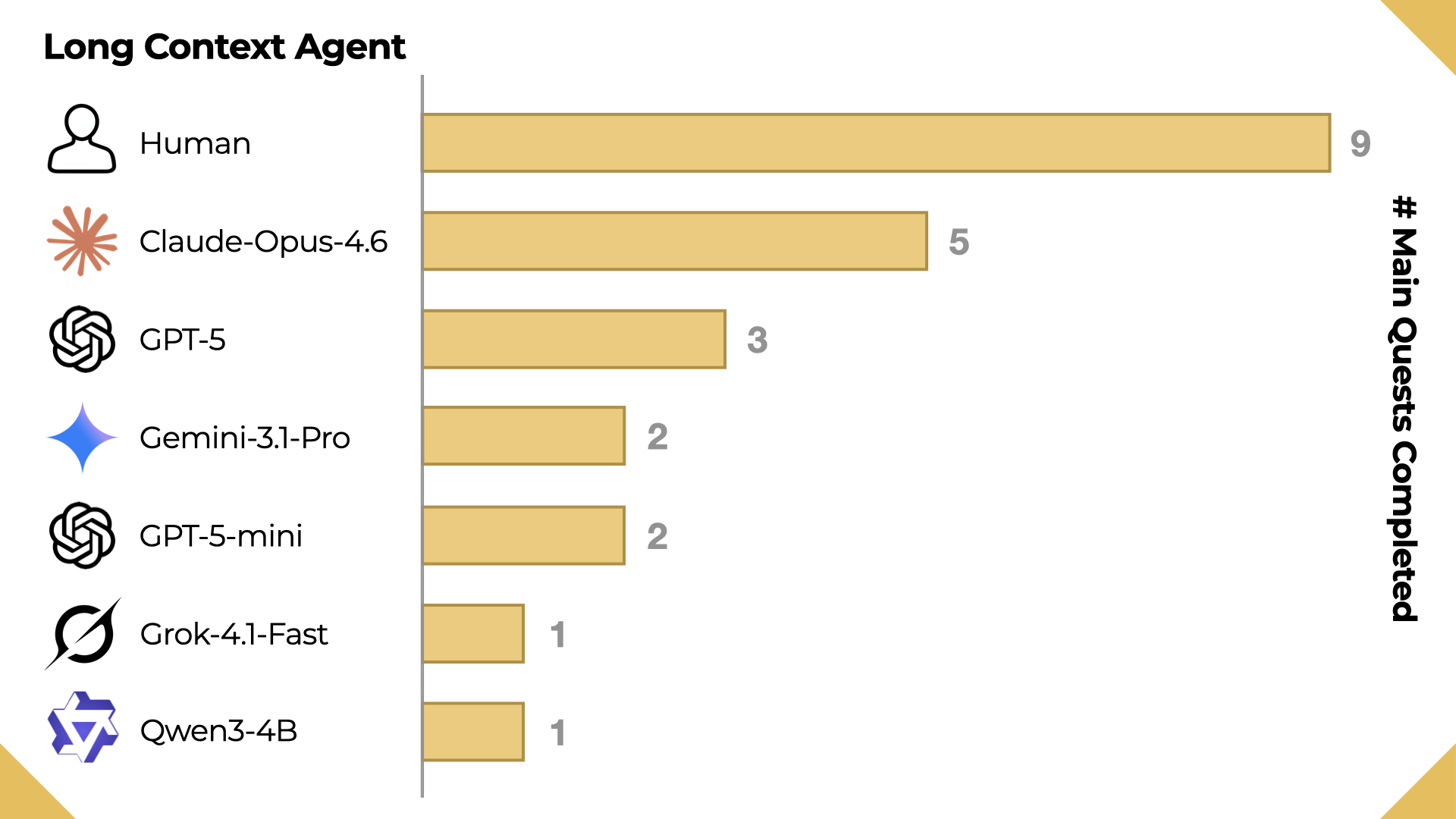
Even with the best-performing agent paradigm that uses full past experience as memory, frontier LLMs are still behind human-level performance.
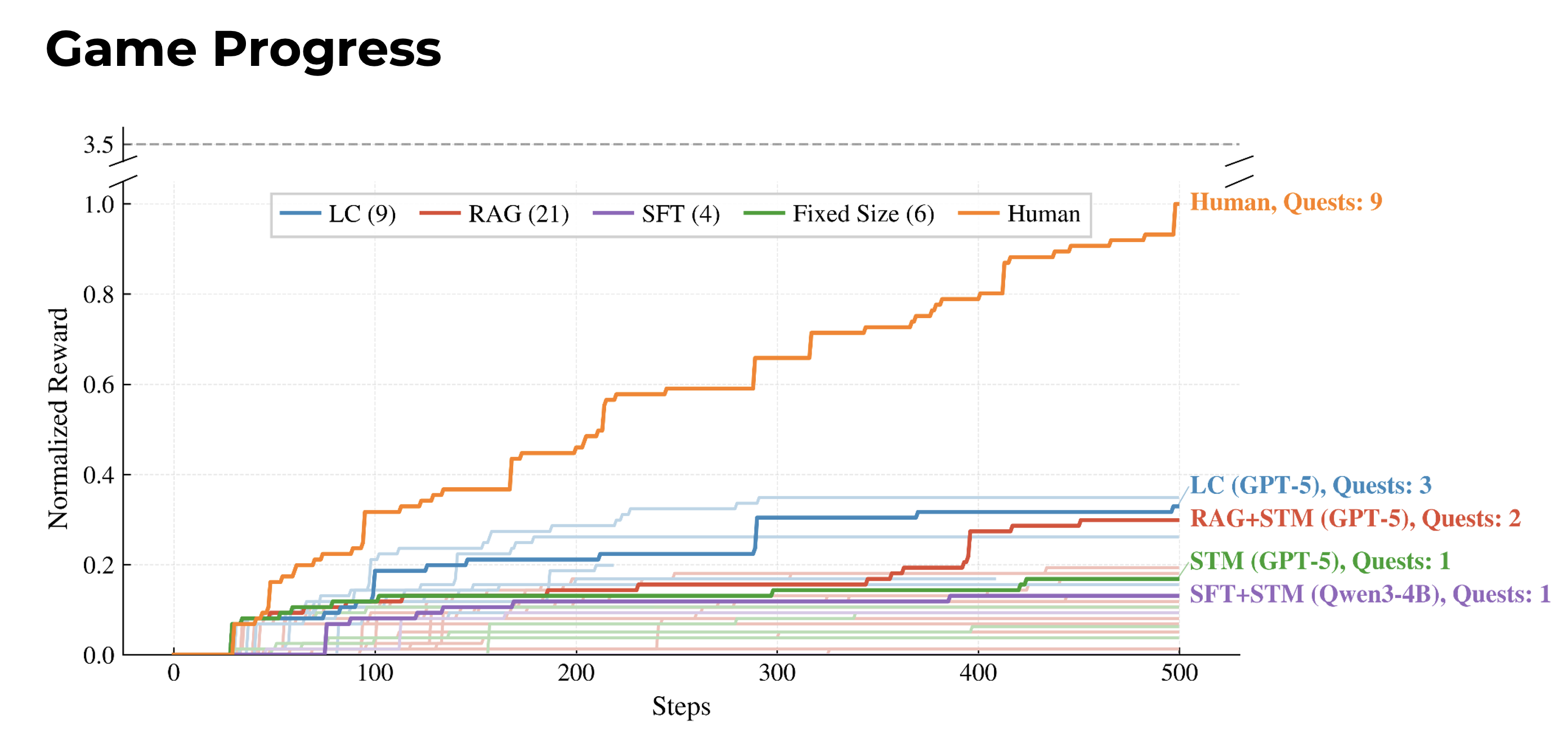
Long Context is the best performing agent paradigm in terms of main quest completion, with total supplementary reward used as a tiebreaker.
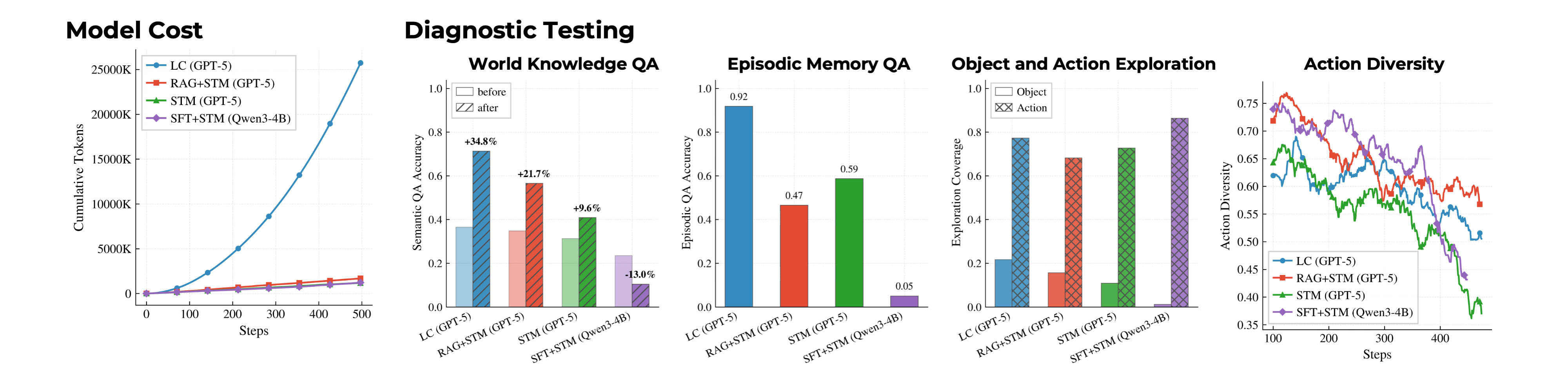
Diagnostic results are strongly correlated with game progress performance. Additionally, the Long Context agent has a quadratic token cost.
Critical limits across all five key abilities
Agents show myopic exploration that ignores useful objects, repetitive action loops despite corrective feedback, semantic hallucinations about crafting recipes and world rules, inability to acquire procedural combat strategies or note-taking skills, and frequent failure to re-anchor on primary objectives after completing subgoals.
Performance scales with memory capacity and reasoning ability
The Long Context agent achieves the strongest game progress, and performance degrades with weaker backbones (GPT-5 > GPT-5-mini > Qwen3-4B). Even the best-performing model, Claude Opus 4.6, still falls well below human performance.
Diagnostic metrics strongly correlate with game progress
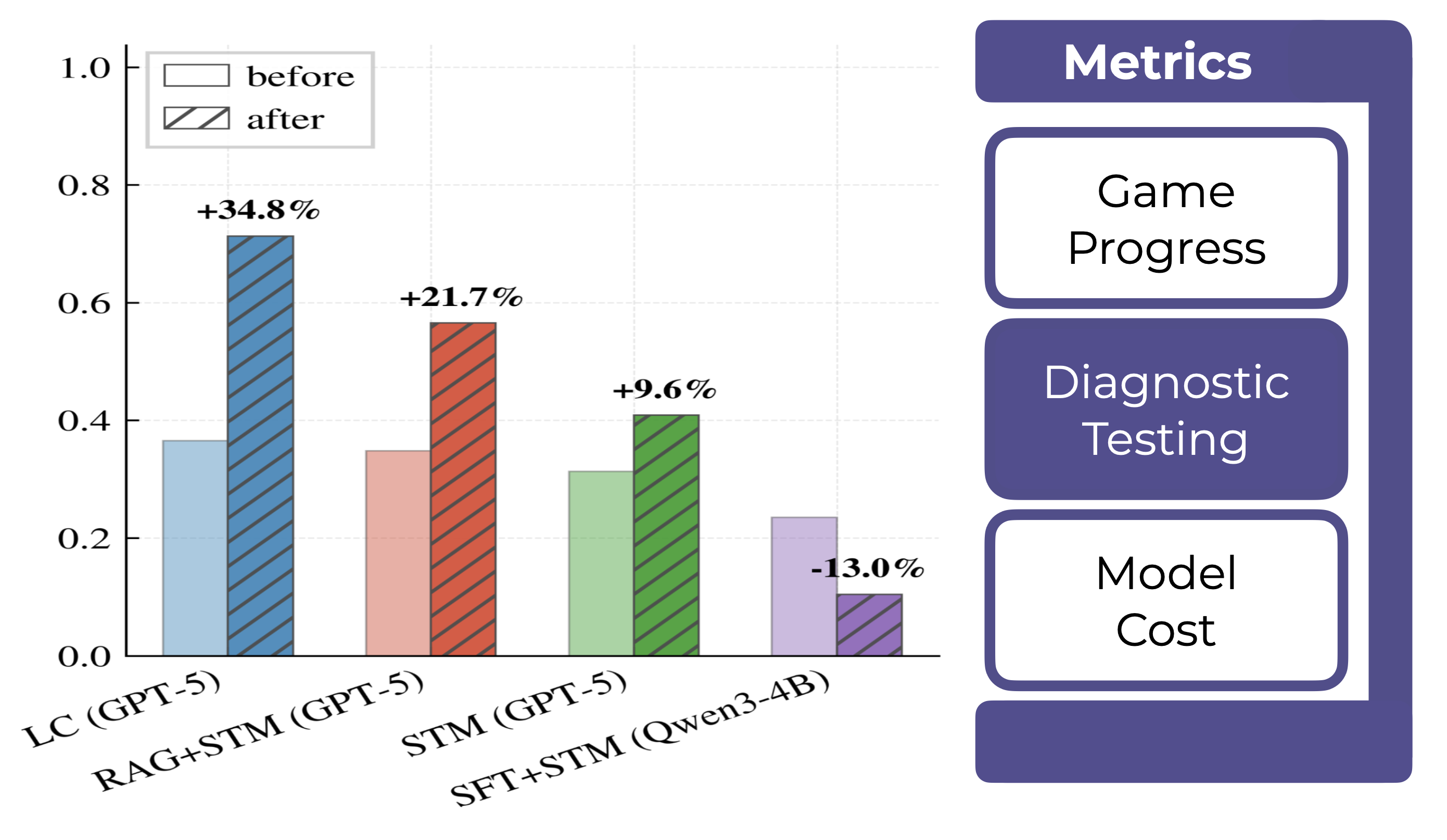
World Knowledge QA accuracy (+34.8% for the best agent), Episodic Memory QA accuracy, object/action exploration coverage, and action diversity all show strong positive correlation with cumulative reward. Declining action diversity coincides with reward plateaus.
Procedural generation remains contamination-resistant
Together with the performance among LLM-based agents, the low accuracy in World Knowledge QA before gameplay shows that the games generated by AgentOdyssey are not saturated by frontier models, indicating no or only limited data contamination.
Short-term memory consistently boosts performance
Adding short-term memory improves both RAG and SFT agents. Game progress and World Knowledge QA accuracy increase monotonically with short-term memory size. SFT agents augmented with short-term memory outperform vanilla short-term memory agents, confirming that parametric updates serve as effective long-term memory.
SFT agents exhibit catastrophic forgetting after training
The SFT agents show decreased World Knowledge QA accuracy after training and very low Episodic Memory QA accuracy. This suggests that test-time training can degrade general language capability through catastrophic forgetting, so future agent training methods should focus on continuously acquiring environmental knowledge and skills without catastrophic forgetting.
Reflection and summarization do not help reasoning models
Explicit reflection and summarization mechanisms provide no benefit for reasoning-capable models, which likely perform implicit reflection during their reasoning process. Adding reflection also accelerates context window exhaustion for Long Context agents.
Long Context agents face quadratic token cost
While Long Context agents perform best, their cumulative token usage grows quadratically with steps, limiting the meaningful horizon under fixed budgets. Other paradigms (RAG, SFT, STM) scale linearly and can sustain longer deployments.
Acknowledgements
This project was sponsored by a generous award from Amazon. We thank our colleagues and collaborators for their input on an earlier draft of this work. TS also acknowledges Lambda for its support in providing computational resources.
Citation
If you find AgentOdyssey useful, please cite our paper:
@article{zhang2026agentodyssey, title = {AgentOdyssey: Open-Ended Long-Horizon Text Game Generation for Test-Time Continual Learning Agents}, author = {Zhang, Zheyuan and Wen, Zehao and Zhang, Alvin and Wang, Andrew and Xie, Jianwen and Khashabi, Daniel and Shu, Tianmin}, journal = {arXiv preprint arXiv:2606.24893}, year = {2026}, }